Quantization (post-training quantization) your (custom mobilenet_v2) models .h5 or .pb models using TensorFlow Lite 2.4

Short summary:
In this article, I will explain what is quantization, what types of quantization exist at this time, and I will show how to quantization your (custom mobilenet_v2) models .h5 or .pb using TensorFlow Lite only for CPU Raspberry Pi 4.
Code for this article is available here.
Note before you start:
So, let’s start :)
Hardware preparation:
Software preparation:
1) What the quantization model in the context of TensorFlow?
This is a model which doing the same as the standard model but: faster, smaller, with similar accuracy. Like in the gif below :)

or this :)

Big turtle is simple CNN (.h5 or .pb ) model.
A baby turtle is a quantization model.
:)
Put it simply, usually, we use models with next weights (465.949494 and etc …) these weights usually are floating-point numbers.
In the screenshot below, you can see these floating-point numbers for weights— it’s just an example.
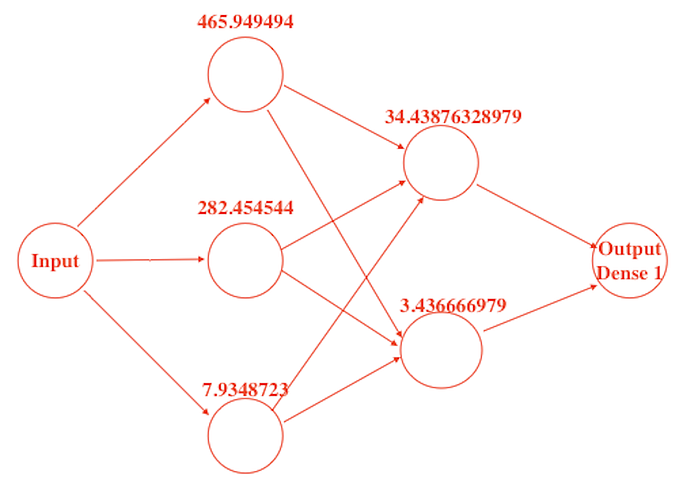
But after quantization, these weights can be changed to …
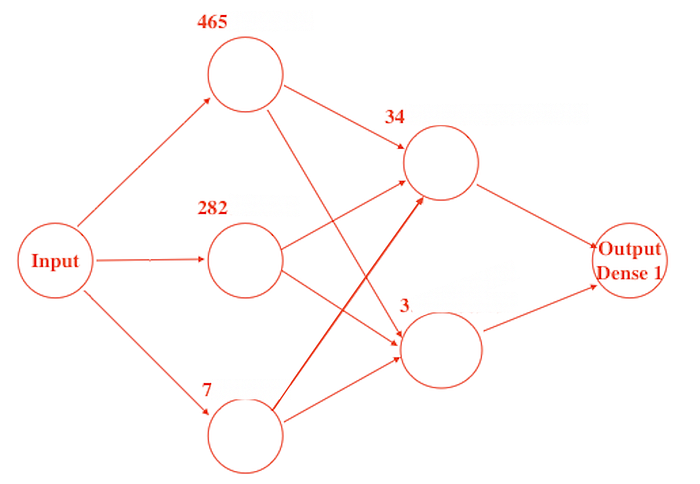
So it this is a rough example of what quantization is.
2) So what the difference between the quantization model and simple (.h5 or .pb or etc …)?
1. Is decrease model size
For example:
We had .h5 or tflite or etc … simple CNN model (for image-classification) file with size 11.59 MB.After quantization model he will next result:
model will be 3.15 MB.
2. Less latency for recognizing one image
Fow example:
We had .h5 or tflite simple CNN model (for image-classification) and latency for recognize one image 300ms on CPU.After quantization model he will next result:
170ms on CPU
3. Loss of productivity up to 1 percent
Fow example:
We had .h5 or tflite simple CNN model (for image-classification) and accuracy was 99%After quantization model he will next result:
accuracy will 99%
3) What types of quantization exist?
Basically exist 2 types of quantization
- Quantization-aware training;
- Post-training quantization with 3 different approaches (Post-training dynamic range quantization, Post-training integer quantization, Post-training float16 quantization ).
p.s.: In this article, I will explain the second approach.
4) How I can do post-training quantization?
Notebook with these examples here.
1 How to convert .h5 to quantization model tflite ( 8-bits/float8):
1.0 using Optimize.DEFAULT
import tensorflow as tfmodel = tf.keras.models.load_model("/content/test/mobilenetv2.h5")
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]tflite_quant_model = converter.convert()#save converted quantization model to tflite format
open("/content/test/quantization_DEFAULT_8bit_model_h5_to_tflite.tflite", "wb").write(tflite_quant_model)
1.1 using Optimize.OPTIMIZE_FOR_SIZE
import tensorflow as tfmodel = tf.keras.models.load_model("/content/test/mobilenetv2.h5")
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]tflite_quant_model = converter.convert()#save converted quantization model to tflite format
open("/content/test/quantization_OPTIMIZE_FOR_SIZE_8bit_model_h5_to_tflite.tflite", "wb").write(tflite_quant_model)
1.2 using Optimize.OPTIMIZE_FOR_LATENCY
import tensorflow as tfmodel = tf.keras.models.load_model("/content/test/mobilenetv2.h5")
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_LATENCY]tflite_quant_model = converter.convert()#save converted quantization model to tflite format
open("/content/test/quantization_OPTIMIZE_FOR_LATENCY_8bit_model_h5_to_tflite.tflite", "wb").write(tflite_quant_model)
2 How to convert .h5 to quantization model tflite ( 16-bits/float16):
2.0 using Optimize.DEFAULT
import tensorflow as tfmodel = tf.keras.models.load_model("/content/test/mobilenetv2.h5")
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]tflite_quant_model = converter.convert()#save converted quantization model to tflite format
open("/content/test/quantization_DEFAULT_float16_model_h5_to_tflite.tflite", "wb").write(tflite_quant_model)
2.1 using Optimize.OPTIMIZE_FOR_SIZE
import tensorflow as tfmodel = tf.keras.models.load_model("/content/test/mobilenetv2.h5")
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
converter.target_spec.supported_types = [tf.float16]tflite_quant_model = converter.convert()#save converted quantization model to tflite format
open("/content/test/quantization_OPTIMIZE_FOR_SIZE_float16_model_h5_to_tflite.tflite", "wb").write(tflite_quant_model)
2.2 using Optimize.OPTIMIZE_FOR_LATENCY
import tensorflow as tfmodel = tf.keras.models.load_model("/content/test/mobilenetv2.h5")
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_LATENCY]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()#save converted quantization model to tflite format
open("/content/test/quantization_OPTIMIZE_FOR_LATENCY_float16_model_h5_to_tflite.tflite", "wb").write(tflite_quant_model)
5) What the result will be after post-training quantization model mobilenet_V2?
I created 8 python scripts that will testing speed recognize for 100 images on the Raspberry Pi 4. To run these tests you can run the next commands, but only sequential.
#clone my repo
git clone https://github.com/oleksandr-g-rock/Quantization.git#go to directory
cd Quantization#run testspython3 test_h5.pypython3 test_tflite.pypython3 OPTIMIZE_FOR_SIZE_float16.pypython3 DEFAULT_float16.pypython3 OPTIMIZE_FOR_LATENCY_float16.pypython3 OPTIMIZE_FOR_SIZE_float8.pypython3 DEFAULT_float8.pypython3 OPTIMIZE_FOR_LATENCY_float8.py
These 8 scripts will be testing the next models:
- Tensorflow .h5
- Just converted Tensorflow Lite .tflite
- Tensorflow Lite OPTIMIZE_FOR_SIZE/DEFAULT/OPTIMIZE_FOR_LATENCY float16 quantization model tflite
- Tensorflow Lite OPTIMIZE_FOR_SIZE/DEFAULT/OPTIMIZE_FOR_LATENCY float8 quantization model tflite
My result after testing below and here:
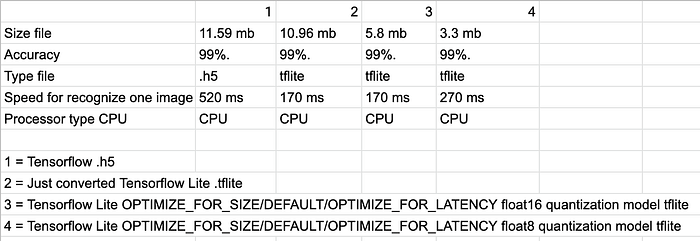
Result:
1 Results about resizing model:
- After converted models from .h5 to tflite — model size was 11.59 MB and became 10.96 MB
- After quantization models from .h5 to tflite using Tensorflow Lite OPTIMIZE_FOR_SIZE/DEFAULT/OPTIMIZE_FOR_LATENCY float16 — model size was 10.96 MB and became 5.8 MB
- After quantization models from .h5 to tflite using Tensorflow Lite OPTIMIZE_FOR_SIZE/DEFAULT/OPTIMIZE_FOR_LATENCY float8 — model size was 5.8 MB and became 3.3 MB
So I guess the results of the resizing model are perfect.
2 Results about speed for recognize, the results are not so good as I expected, but speed recognition is optimal (because it 99%) for Raspberry Pi.
Code for this article is available here.

